
Towards a sustainable enabler for smart and green mobility data reuse.
Motivation

Shared Mobility players (e.g., bike sharing, micromobility, ....) deliver datasets about their offering in a myriad of ways and formats. Integrating all this data and publishing it in a uniform user-friendly way is non-trivial and costly. Solving the issue of shared mobility data harmonization and publication is crucial to allow answering questions like “How many bikes will be available when my train arrives?”. The proposed architecture of the smart mobility publication pipeline enables harmonized publication of these data sources, resulting in semantical and technical interoperability and thus allowing for easier integration by data integrators, app builders and reusers.
Data Sets description
Data Sets description: In order to achieve such integration, the existing OSLO vocabularies on mobility data from the OSLO “trips en aanbod” will be broadened to a green mobility scope. Not only will the data standards be extended with the Shared mobility information, existing Flemish data standards will be aligned with european standards as well. As such, we will seek alignment between existing OSLO mobility data models and FIWARE data models by contributing to a shared goal: the creation of a GreenMov core vocabulary. The datasets will thus follow the NGSI-LDF paradigm of publishing cacheable NGSI-LD resources. The OSLO vocabularies will finally be adapted to the NGSI-LD standard and therefore the creation of the corresponding smart data models will be feasible, once tested within the pilot. It includes some examples of the payloads, documented description of the different properties and a validation resource (json schema) for the payloads.
European Data portal relevance

The Flemish regional data portal is hosted and maintained by AIV. This portal is publishing over 8000 Open Datasets of Flemish Cities and administrations. AIV is also subscribing to the open data charter of Flanders, originated in the Smart Flanders program . This subscription includes metadata principles and the use of the Flemish regional data portal . This regional data portal is federated to the European Data portal, and thus when generating datasets during this project, they will also automatically appear on the European one. Today you also already find datasets such as the Blue Bike locations for the city of Antwerp , as the City of Antwerp has this as a dataset on their local portal. However, when the Flemish level would now publish a dataset of Blue Bike locations for all of Flanders, the Antwerp dataset would become deprecated without the European data portal being aware of that. Therefore, we will invest heavily in Feature 4 to annotate our datasets with machine interpretable metadata (for instance with SHACL shapes) so we can have a smarter source selection strategy.
Required mobility services
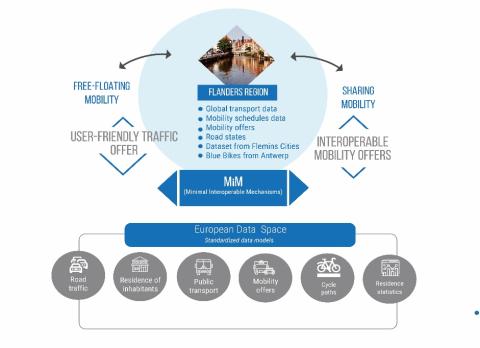
To stimulate maximum reuse of the published data, we will focus on a source selection component that will be the enabler for scalable green mobility use cases in Flanders. By focussing on the semantics and technical interoperability supported by the CEF building blocks, we see this as a stepping stone towards a scalable reuse and ease-of-use of the green mobility data by third parties. For example, this would make it possible to have automated source selection when trying to predict whether there would be bikes available at the moment when the train arrives in your destination station.
Current use of Context Broker
By using atomic reusable components, the unified data publishing pipeline will enable broad adoption of the standards and enhance technical interoperability. The first step is to map the publisher's data to the open linked data Vocabulary and to publish them as event streams. This approach allows us to archive the entire history of the data set for later querying and analysis. This can be done using the first reusable building block. An NGSI-LDF component will expose both the event stream as well as the historical data APIs to connect to NGSI-LD compliant components.